實習內容概要:


我們的資料處理和一款由紐西蘭懷卡托大學用Java開發的數據挖掘常用軟體-----WEKA息息相關,Weka的全名是懷卡托智能分析環境(Waikato Environment for Knowledge Analysis),他的特色不僅僅是免費,非商業化,而且他的原始碼可在其官方網站下載,其軟體Logo為紐西蘭的一種鳥類:WEKA,正巧與其名稱縮寫同名。
我的數據資料來源,是運用Thomson Innovation專利資料庫蒐集美國專利局中RFID產業之核准專利資料。運用以下三種方式去進行專利價值預測模型的建立並進行專利價值的預測:
1. AIS方法(類免疫演算法,Artificial Immune Algorithm)
將問題目標值視為抗原,另外將問題之設計解視為抗體,針對不同的抗原,免疫系統會自動搜尋適合的抗體與之結合,並計算抗體和抗原間的親和力,如果親和力已經收斂即終止運算。如果親和力尚未收斂則進行抗體繁殖、分化作用及篩選過程,緊接著重新計算抗體和抗原間的親和力,反覆以上的步驟直到親和力收斂為止。
2. SVM方法(支持向量機,Support Vector machine)
於1990年代由Vapnik提出,可有效判別資料線性與非線性資料的規則。經常用於預測與分類問題,也可運用於處理大量的專利資訊上。Ercan以支持向量機建立根據歷史的專利特徵及專利核可狀態,建立可判斷專利核可與否之預測模型。
3. DT方法(決策樹,Decision Tree)
決策樹(Decision Tree, DT)是用來處理分類、預測問題之樹狀結構,任何一件決策或事件都有機會引出多個事件,因而導致不同結果,決策樹將決策過程畫成分支圖。其本質屬於貪婪演算法(Greedy Algorithm),將測試資料以遞迴方式挑選最適之屬性並反覆將樣本分隔,以由上至下之方式建立決策樹,其中根節點(Root Node)為決策點,每個分支(Branch)代表為測試結果,葉節點(Leaf Node)代表類別值。
AIS方法流程圖:
系統介面

迴歸分析:
邏輯解釋:
用於建立和使用具有脊估計器的多項邏輯回歸模型的類。
然而,與leCessie和van Houwelingen(1992)的論文相比,有一些修改:
如果對於具有m個屬性的n個實例存在k個類,則要計算的參數矩陣B將是m *(k-1)矩陣。
除了最後一個類之外,類j的概率是
Pj(Xi)= exp(XiBj)/((sum [j = 1 ..(k-1)] exp(Xi * Bj))+ 1)
最後一班有概率
1-(總和[J = 1 ..(K-1)]點Pj(十一))
= 1 /((sum [j = 1 ..(k-1)] exp(Xi * Bj))+ 1)
因此,(負)多項對數似然:
L = -sum [i = 1..n] { sum [j = 1 ..(k-1)](Yij * ln(Pj(Xi))) +(1 - (sum [j = 1 ..(k-1)] Yij)) * ln(1-sum
[j = 1 ..(k-1)] Pj(Xi)) } +脊*(B ^ 2)
為了找到L最小化的矩陣B,使用準牛頓法來搜索m *(k-1)變量的優化值。

分析屬性:
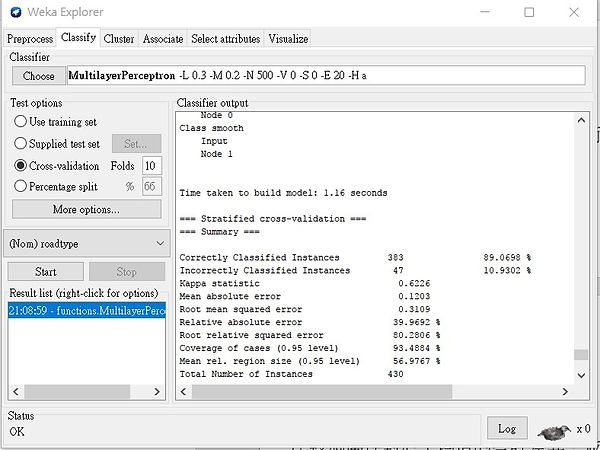
利用WEKA進行運算
紀錄結果: